
Technical SEO Checklist for UK Business Websites
Search visibility problems rarely begin with a dramatic collapse.
In most cases, they emerge gradually. Rankings become less consistent. Organic traffic plateaus despite ongoing content investment. New pages take longer to index. Competitors begin appearing above websites that have historically performed well. Nothing appears obviously broken, yet something is clearly limiting growth.
When business owners encounter this situation, the first instinct is often to focus on content. More blog articles. More landing pages. More keywords. More backlinks.
Sometimes that is the right answer.
Quite often, it is not.
Across technical SEO audits, one pattern appears repeatedly: websites invest heavily in visibility strategies while overlooking the infrastructure that allows those strategies to work effectively in the first place. Search engines cannot rank pages they struggle to discover, interpret or trust. A technically weak website can undermine even the strongest content strategy.
The challenge is that technical SEO remains largely invisible. Users rarely notice crawlability issues, indexation conflicts, inefficient site architecture or rendering problems. Search engines do.
That distinction matters.
A website may look modern, load reasonably quickly and generate enquiries while simultaneously sending mixed signals to Google. Over time, those signals accumulate. What initially appears to be a minor technical imperfection can evolve into a genuine growth constraint.
This guide explores the technical SEO checks that deserve regular attention on UK business websites. Rather than providing a generic list of tasks, it focuses on the areas that consistently influence organic performance, explains why they matter and highlights the issues that repeatedly surface during technical SEO reviews, website migrations and redesign projects.
The Hidden Layer Beneath Every Successful SEO Strategy
Technical SEO is often misunderstood because it rarely produces immediate visible results.
Publishing a new piece of content creates something tangible. Launching a link building campaign feels proactive. Improving conversion rates produces measurable outcomes. Technical optimisation tends to operate in the background, quietly supporting everything else.
That support role sometimes leads organisations to underestimate its importance.
In reality, technical SEO functions much like the foundations beneath a building. Nobody admires the foundations. They are not the reason people enter the building. Yet their quality determines how much can safely be built above them.
The same principle applies to websites.
Search engines need to crawl pages efficiently, understand relationships between content, process technical signals correctly and evaluate site quality without unnecessary friction. Every obstacle placed within that process increases complexity. Sometimes the impact is small. Sometimes it affects an entire section of a website.
One of the more interesting observations from recent years is that technical SEO has become more important as websites have become more sophisticated. Modern business websites are no longer simple collections of static pages. They often contain dynamic content, integrated CRM systems, booking functionality, advanced analytics, personalisation features, third-party scripts, ecommerce components and multiple content hubs.
Each additional layer introduces potential opportunities. It also introduces potential failure points.
A website containing twenty pages and minimal functionality can often perform adequately despite technical imperfections. A website containing hundreds or thousands of URLs operates under different conditions. Search engines are no longer evaluating isolated pages. They are evaluating a connected ecosystem.
At that point, architecture, crawl efficiency, internal linking, rendering behaviour and index management become increasingly important.
How Google Experiences Your Website Differently From Your Visitors
 One of the most useful ways to understand technical SEO is to stop viewing a website through the eyes of a customer and start viewing it through the eyes of a search engine.
One of the most useful ways to understand technical SEO is to stop viewing a website through the eyes of a customer and start viewing it through the eyes of a search engine.
A potential customer arrives on a page and immediately begins evaluating visual design, messaging, navigation and credibility. Humans process information remarkably quickly. Within seconds, they develop impressions about professionalism, trustworthiness and relevance.
Google approaches the same page very differently.
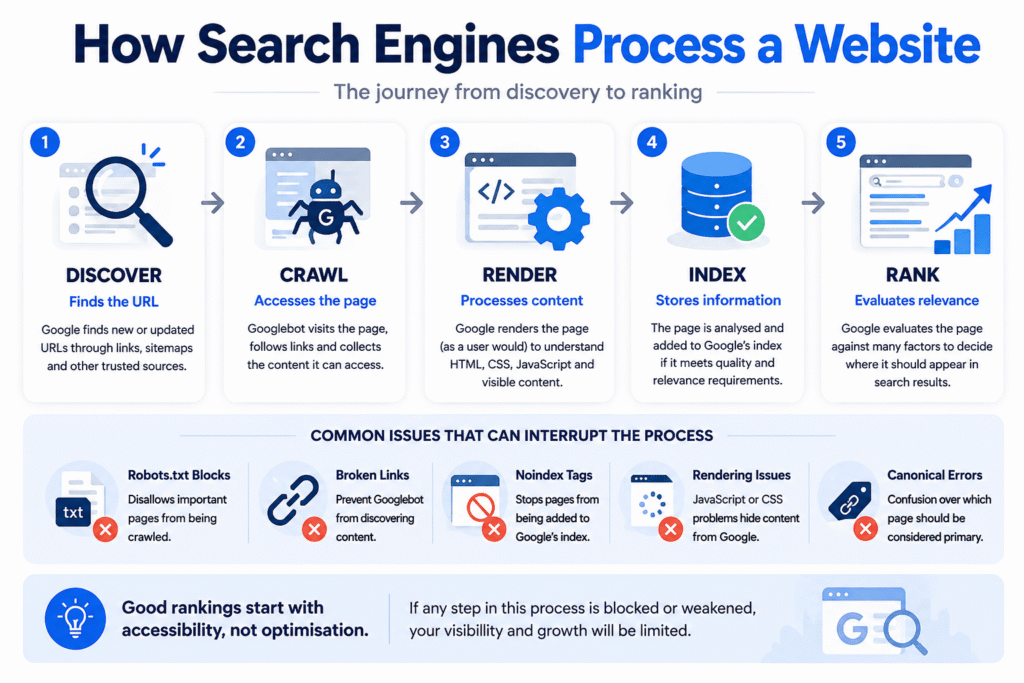
Before rankings become possible, several technical processes must occur successfully. The page must first be discovered. It then needs to be crawled, rendered, interpreted and evaluated. Only after those stages can Google determine whether the page deserves inclusion within search results and how it compares to competing alternatives.
Problems at any stage can interrupt the process.
A page that cannot be discovered cannot be crawled. A page that cannot be crawled cannot be indexed. A page that is not indexed cannot rank.
That sequence sounds straightforward, yet it is responsible for a surprising number of visibility issues.
During technical audits, it is not unusual to find commercially important pages sitting several layers deep within a website structure, receiving minimal internal authority and limited crawl attention. The pages exist. The content exists. The services are relevant. Search visibility remains weak because the supporting technical signals are insufficient.
This is one reason technical SEO should not be viewed simply as optimisation. In many respects, it is accessibility. It ensures search engines can access, understand and evaluate content as efficiently as possible.
When that process becomes easier, everything built on top of it becomes more effective.
Where Technical Problems Usually Begin
One of the biggest misconceptions surrounding technical SEO is that websites suddenly develop technical issues.
Most do not.
Technical problems are typically the by-product of growth, change or complexity.
A website launches with a clean structure. New services are added. Additional content categories are introduced. Marketing campaigns create landing pages. Developers implement new functionality. Plugins accumulate. Tracking systems expand. Design updates alter templates. Over several years, hundreds of small changes gradually reshape the website.
None of those changes are inherently problematic.
Together, they can create an environment where technical debt begins to emerge.
Technical debt is a concept that deserves more attention within SEO discussions. It refers to the accumulation of legacy decisions, temporary fixes and structural compromises that become increasingly difficult to manage over time. The website continues functioning, but efficiency slowly deteriorates.
Internal linking becomes inconsistent. Redirect chains expand. Duplicate content appears. Legacy pages remain accessible. Multiple versions of similar URLs emerge. Indexation becomes harder to control.
Eventually, the effects become visible through slower organic growth, reduced crawl efficiency or declining visibility.
Understanding this progression is important because it changes how technical SEO should be approached. The goal is not perfection. The goal is preventing manageable issues from evolving into larger structural constraints.
Start With Crawlability: Can Search Engines Reach What Matters?
Before Google can evaluate quality, relevance or authority, it needs access.
Crawlability forms the foundation of every technical SEO review because every other optimisation depends on it. If search engines struggle to access important content, improvements elsewhere may have limited impact.
One of the more common findings during audits is that crawlability problems often remain hidden for long periods. Users continue navigating the website without difficulty. Enquiries continue arriving. Internal teams assume everything is functioning normally.
Meanwhile, search engines may be encountering unnecessary barriers.
Sometimes those barriers originate within a robots.txt file that has not been reviewed since launch. Sometimes they emerge through navigation changes that unintentionally increase crawl depth. Occasionally they appear after redesign projects where entire content sections become disconnected from the wider website.
The underlying causes vary. The outcome is usually the same: search engines spend more effort discovering content than they should.
A healthy website structure allows Google to move efficiently between important pages, understand topical relationships and identify which areas deserve attention. An inefficient structure forces search engines to work harder while simultaneously reducing clarity.
This is why crawlability should always be the starting point.
Before discussing rankings, authority or optimisation opportunities, it makes sense to confirm that search engines can actually reach the pages that matter most.
Robots.txt: Small File, Significant Consequences
Few technical SEO elements have the potential to create disproportionate damage as quickly as a poorly configured robots.txt file.
The file itself is simple. Its purpose is straightforward. It provides instructions regarding which sections of a website search engines should or should not crawl.
The problem is not complexity.
The problem is oversight.
Development environments occasionally launch with restrictive directives still active. Legacy instructions remain in place long after website migrations. Entire content sections become inaccessible because nobody revisited a configuration created months or years earlier.
These scenarios are less common than they once were, but they still occur often enough to justify routine checks.
Even smaller issues deserve attention. Search engines increasingly rely on JavaScript rendering and modern website frameworks. Restricting access to resources that support rendering can create unintended consequences, particularly on more complex websites.
A robots.txt review should therefore focus not only on blocking directives, but also on whether the file still reflects the current structure and priorities of the website.
Crawl Depth: A Problem That Often Grows Quietly
 Crawl depth rarely appears on a marketing dashboard. It does not generate alarming notifications. Clients seldom ask about it during meetings.
Crawl depth rarely appears on a marketing dashboard. It does not generate alarming notifications. Clients seldom ask about it during meetings.
Yet it remains one of the more revealing indicators of how efficiently a website is structured.
As websites evolve, content naturally becomes more layered. New service areas are introduced. Resource centres expand. Category structures become more sophisticated. Over time, important pages can drift further away from the homepage without anyone consciously planning for it.
In moderation, that is not a problem.
The issue emerges when commercially valuable pages become buried beneath multiple levels of navigation and internal hierarchy. Search engines can still discover them, but discovery becomes less efficient. Internal authority must travel through more layers. Signals become weaker.
A useful exercise is to identify the pages that matter most commercially and ask a simple question: how many clicks would it realistically take for both users and search engines to reach them?
The answer often reveals opportunities that have little to do with keywords and everything to do with accessibility.
The Hidden Cost of Orphan Pages
Orphan pages represent one of the most overlooked technical SEO issues because they often exist outside normal website workflows.
The pages themselves are not broken. They load correctly. They may even contain valuable information. The problem is that nothing meaningfully connects them to the rest of the website.
Most orphan pages appear after periods of change. A website redesign removes older navigation pathways. A campaign concludes and its landing pages are forgotten. Content restructuring leaves historical resources disconnected from their original categories.
From a search engine perspective, these pages exist in isolation.
Google may still discover them through XML sitemaps, historical crawl data or external links. Yet discovery becomes less reliable and internal authority becomes significantly weaker.
Some of the most valuable pages uncovered during technical audits are orphan pages that have simply been left behind as the website evolved.
Finding them is often straightforward. Understanding why they became orphaned tends to reveal broader architectural issues.
Internal Linking as an Infrastructure System
Internal linking discussions frequently focus on SEO tactics.
Anchor text optimisation. Link placement. Authority distribution.
Those considerations matter, but they miss a larger point.
Internal linking is fundamentally an infrastructure system.
It determines how information flows throughout a website.
A well-designed internal linking structure helps search engines understand relationships between topics, identify priority pages and recognise expertise within specific subject areas. It also helps users move naturally through content without feeling trapped within isolated sections.
One recurring pattern appears on growing websites. New content is published consistently, but older content receives little maintenance. As a result, recently published pages become increasingly connected while historical resources gradually lose visibility within the site architecture.
This creates a subtle form of content decay.
The content itself may remain relevant. The pathways leading towards it become weaker.
Strong internal linking strategies are rarely about adding more links. They are about creating better relationships between pages that genuinely belong together.
XML Sitemaps Still Matter — Just Not in the Way Many People Think
XML sitemaps are sometimes treated as a solution to crawlability problems.
They are not.
A sitemap cannot compensate for poor architecture, weak internal linking or significant crawl barriers. Search engines still rely primarily on the structure of the website itself.
What XML sitemaps do provide is clarity.
They help search engines understand which URLs the website considers important. They reduce ambiguity. They provide an additional discovery pathway.
The problem is that many sitemaps are generated automatically and then ignored indefinitely.
Technical audits regularly uncover sitemaps containing redirected URLs, outdated pages, non-indexable content and legacy sections that should have been removed years earlier.
An effective sitemap should act as a reliable representation of the website’s current indexable content. If it no longer reflects reality, its value diminishes significantly.
When Pages Exist But Still Fail to Rank
Few technical SEO frustrations are more confusing than discovering that important pages are not appearing in search results despite being fully accessible on the website.
The pages exist.
The content exists.
The services are relevant.
Yet visibility remains limited.
This is where indexability becomes critical.
Crawling and indexing are closely related, but they are not the same process. Search engines may successfully access a page while simultaneously deciding not to include it within their searchable index.
For businesses, the distinction matters because an unindexed page cannot generate organic visibility regardless of its quality.
What Google Search Console Often Reveals
One of the more revealing aspects of technical SEO audits involves analysing index coverage data.
Google frequently provides clues about underlying issues long before rankings are affected.
Pages classified as “Crawled – Currently Not Indexed” deserve particular attention.
This status does not necessarily indicate a technical fault. More often, it reflects uncertainty.
Google has found the page but remains unconvinced about its value relative to other content it has already indexed.
That uncertainty can originate from several sources. Duplicate content, weak internal authority, thin content, inconsistent signals and structural issues may all contribute.
The important point is that indexing should never be assumed.
It should be verified.
Canonical Tags: One of the Most Misunderstood Technical Signals
Canonical tags are designed to simplify Google’s decision-making process.
In practice, they often complicate it.
On straightforward websites, canonical implementation is usually relatively simple. Larger websites introduce additional complexity. Ecommerce filters generate alternative URLs. Tracking parameters create variations. Similar content appears across multiple locations.
Canonical tags help indicate which version should be treated as the preferred version.
The challenge arises when those signals become inconsistent.
A canonical tag may point towards a different page than intended. Self-referencing canonicals may be missing entirely. Template changes can introduce errors across hundreds of URLs simultaneously.
What makes canonical issues particularly problematic is that they often remain invisible to users.
The website appears normal.
Search engines receive conflicting instructions.
Over time, those conflicts can affect indexation, authority distribution and ranking stability.
This is one reason canonical reviews should always be approached strategically rather than mechanically. The goal is not simply ensuring tags exist. The goal is ensuring they accurately reflect the preferred structure of the website.
Why Growing Websites Need to Think About Crawl Budget
Crawl budget is frequently discussed within enterprise SEO circles and then dismissed by smaller organisations as irrelevant.
That assumption is not always correct.
Most local business websites will never encounter serious crawl budget constraints. Larger content websites, ecommerce platforms and rapidly expanding resource hubs often operate under different conditions.
Search engines allocate finite resources when crawling websites. The larger and more complex a website becomes, the more important crawl efficiency becomes.
If Google spends excessive time crawling duplicate URLs, parameter variations, outdated content or low-value sections, fewer resources remain available for pages that genuinely matter.
The issue rarely appears overnight.
It develops gradually as content expands and technical complexity increases.
Signs may include delayed indexing, inconsistent crawl patterns and important pages receiving less frequent attention than expected.
For growing websites, crawl budget should not be viewed as an advanced SEO concept. It should be viewed as an efficiency concept.
The easier a website is to crawl, the more effectively search engines can focus on valuable content.
The Increasing Importance of JavaScript SEO
A decade ago, most business websites were relatively straightforward from a rendering perspective.
Today’s websites are considerably more sophisticated.
Modern development frameworks, interactive interfaces and dynamic content systems have transformed how websites are built. These technologies create exceptional user experiences when implemented correctly.
They also introduce new technical SEO considerations.
Search engines have become increasingly capable of processing JavaScript. That does not mean every implementation performs equally well.
Rendering delays, blocked resources, dynamically loaded content and complex application structures can all influence how efficiently content is discovered and interpreted.
This becomes particularly relevant during website redesign projects where development priorities naturally focus on functionality and user experience.
In some cases, critical content may only become visible after client-side rendering occurs. Search engines can often process this content, but the process may be slower, less predictable or more resource-intensive than traditional HTML delivery.
From an SEO perspective, the objective is not avoiding JavaScript.
The objective is ensuring that search engines can reliably access the content that matters.
As websites continue evolving towards increasingly dynamic architectures, the relationship between development decisions and search visibility is likely to become even more important.
Performance Is No Longer Just a User Experience Discussion
Website speed has been part of SEO conversations for years. The problem is that the discussion is often reduced to a single number.
A PageSpeed score becomes the focus. Teams chase green indicators. Reports highlight technical recommendations. Hours are spent improving metrics that may have little practical impact while larger performance bottlenecks remain untouched.
Real-world performance is more complicated.
A technically healthy website is not necessarily the fastest website possible. It is a website that removes unnecessary friction for both users and search engines.
That distinction matters because performance optimisation is often a balancing act. Businesses want rich visual experiences, advanced functionality, tracking systems, booking tools, CRM integrations and marketing platforms. Every additional feature consumes resources.
The challenge is not eliminating functionality. The challenge is preventing functionality from overwhelming performance.
Across technical audits, it is common to see websites slowed not by a single catastrophic issue but by dozens of smaller decisions that have accumulated over time. Large image files, excessive plugins, poorly optimised scripts, outdated themes and third-party integrations rarely cause problems individually. Together, they can create significant delays.
Search engines increasingly evaluate websites through the lens of user experience. Slow-loading pages create friction. Friction affects engagement. Engagement influences business outcomes long before rankings are considered.
Largest Contentful Paint and What It Actually Tells You
Largest Contentful Paint (LCP) measures how quickly the main visible content appears for users.
On paper, the concept is simple.
In practice, poor LCP scores often reveal deeper infrastructure issues.
A slow server response may be responsible. Oversized images may be delaying rendering. Resource-heavy page builders can introduce unnecessary complexity. Occasionally, hosting environments become the primary bottleneck.
The important point is that LCP should be viewed as a symptom rather than the problem itself.
Improving the score matters. Understanding what caused the score often matters more.
Mobile Performance Deserves Independent Analysis
One recurring mistake involves evaluating website performance exclusively from desktop environments.
Most modern business websites look impressive on high-speed office broadband. Search engines are not evaluating websites solely under those conditions.
Mobile users operate within different environments. Network quality varies. Device capabilities vary. Rendering behaviour changes.
A website that performs adequately on a desktop computer may create a noticeably different experience on mobile devices.
This is particularly relevant for local service businesses, ecommerce brands and organisations that generate significant mobile traffic.
Mobile performance should be reviewed independently rather than treated as an extension of desktop testing.
The differences are often larger than expected.
Structured Data: Creating Clarity Rather Than Chasing Rankings
Few areas of SEO generate as much misunderstanding as structured data.
Part of the confusion comes from how schema markup is discussed within the industry. It is frequently presented as an optimisation tactic capable of improving rankings.
The reality is more nuanced.
Structured data helps search engines understand information more accurately. It reduces ambiguity. It provides context.
Those benefits can support visibility, but not necessarily in the simplistic way many guides suggest.
A useful way to think about schema is as a translation layer between your website and search engines. It helps explain what an organisation is, what a page represents and how different entities relate to one another.
The cleaner those signals become, the easier it is for search engines to interpret content correctly.
Organisation Schema and Business Identity
For UK business websites, organisation schema plays an important role in reinforcing brand identity.
Search engines increasingly rely on entity understanding rather than simple keyword matching. Consistency between website content, structured data and broader online signals helps strengthen that understanding.
Schema alone will not establish authority.
It helps clarify who the organisation is and how it should be understood.
That distinction is subtle but important.
Content Schema and Topical Understanding
For websites publishing guides, insights, industry commentary and educational resources, content-related schema can provide additional context regarding authorship, publication structure and content type.
Its greatest value often appears at scale.
As content ecosystems expand, structured data helps search engines process information more efficiently and understand relationships across a broader content framework.
Again, the objective is clarity rather than manipulation.
Technical SEO tends to perform best when signals reduce confusion rather than attempt to force outcomes.
Security Signals and Technical Trust
Security rarely appears in SEO discussions until something goes wrong.
An expired certificate. Browser warnings. Mixed content errors. Vulnerable plugins.
Yet security forms part of a broader trust framework that influences how websites are perceived by both users and search engines.
HTTPS has long been considered a baseline expectation rather than a competitive advantage. Users expect secure browsing experiences. Search engines expect them as well.
The presence of HTTPS is no longer remarkable.
Its absence is.
Technical audits still uncover websites with inconsistent protocol handling, legacy HTTP references and mixed content warnings that have survived multiple redesigns. These issues may not immediately damage rankings, but they contribute to an overall picture of technical quality.
Search visibility is rarely determined by a single factor. It emerges from the combined strength of many signals. Security contributes to that picture.
The Problem With Mixed Content Warnings
Mixed content warnings often emerge after website migrations, platform changes or years of incremental updates.
An image continues loading through an outdated URL. A script references an insecure resource. Embedded content behaves differently from the rest of the page.
Individually, these issues may appear insignificant.
Collectively, they can undermine user trust and create avoidable technical inconsistencies.
One reason mixed content issues persist is that they are not always visible during routine website management. Everything appears functional.
The underlying technical signals tell a different story.
Redirects: Where Technical Decisions Continue to Echo Years Later
Every website accumulates history.
Pages are renamed. Content is consolidated. Services evolve. Entire sections are redesigned.
Redirects help preserve continuity throughout those changes.
The problem is that redirect management is rarely treated as an ongoing process.
What begins as a sensible migration strategy can gradually become a complex network of historical decisions.
Technical audits regularly uncover redirect chains that have survived multiple redesigns and CMS changes. Nobody deliberately creates them. They emerge through years of incremental development.
The longer they remain, the more inefficiencies they introduce.
Why Redirect Chains Matter
Search engines can usually follow redirect chains successfully.
The issue is efficiency.
A direct route is almost always preferable to a series of unnecessary steps.
Consider a website that has undergone three redesigns over a decade. A service page may have moved multiple times. Each migration introduced another redirect layer.
The final destination still works.
The path towards it becomes increasingly inefficient.
For individual pages, the impact may be minimal. Across hundreds or thousands of URLs, those inefficiencies accumulate.
This is why redirect reviews remain an important component of technical SEO maintenance rather than a one-time migration task.
What Technical Audits Commonly Reveal
One of the recurring themes across technical audits is that websites rarely suffer from a single major issue.
More often, they suffer from the accumulation of dozens of smaller issues.
A redirect chain here.
An orphan page there.
Outdated canonical signals. Legacy sitemap entries. Internal links pointing towards redirected URLs.
Each issue appears manageable in isolation.
Together, they create friction.
That friction influences how efficiently search engines can crawl, interpret and trust the website.
Technical SEO is often less about solving dramatic problems and more about systematically removing unnecessary complexity.
The websites that perform consistently well over time tend to share one characteristic: they are easier for search engines to understand.
That simplicity is rarely accidental.
What Technical SEO Audits Reveal Again and Again
One of the more interesting aspects of technical SEO is how predictable many problems become once enough websites have been reviewed.
The industries change. The platforms change. The businesses themselves may have very different goals. Yet similar technical patterns continue to emerge.
What often surprises business owners is that the biggest ranking constraints are not always dramatic technical failures. In many cases, they are structural inefficiencies that have been accumulating quietly for years.
A website may have excellent content, strong branding and a healthy backlink profile. Organic growth still stalls because technical signals gradually become less coherent as the website expands.
That is why technical audits frequently uncover issues that nobody within the organisation knew existed.
The website appears healthy from the outside.
The underlying infrastructure tells a different story.
A Common Scenario: The Invisible Indexation Problem
Consider a service-based business that regularly publishes new content and continues investing in SEO. Rankings improve initially, then plateau. New pages are added each month, yet overall visibility remains stubbornly flat.
The immediate assumption is often that content quality has become the limiting factor.
Technical reviews frequently reveal a different explanation.
Large numbers of newer pages may never have been fully integrated into the website’s architecture. Internal links are weak. Crawl paths are inconsistent. Google discovers the content eventually, but not with the same confidence or frequency as more established sections.
The content itself is not necessarily the problem.
The environment surrounding the content is.
This distinction matters because it changes where effort should be invested.
Publishing more content rarely solves an accessibility problem.
The Service Page That Quietly Disappeared
Another scenario appears surprisingly often after redesign projects.
A business launches a new website. The design is cleaner. User experience improves. Conversion pathways are modernised.
Everything appears successful.
Several months later, organic traffic begins declining.
Investigations often reveal that key service pages lost visibility during the migration process. Perhaps URL structures changed without complete redirect coverage. Perhaps internal links were removed. Perhaps navigation changes reduced prominence.
None of these decisions were made with the intention of harming rankings.
They simply altered how search engines understood the website.
What makes these situations challenging is that the decline often occurs gradually. By the time the issue becomes obvious, search visibility may have already deteriorated significantly.
Why Website Redesigns Create More SEO Problems Than Most Organisations Expect
Redesign projects are often viewed through the lens of aesthetics and user experience.
Both matter.
Neither represents the greatest SEO risk.
The real challenge lies in preserving search equity while simultaneously changing the structure through which that equity flows.
A redesign can affect:
- URL structures
- Navigation pathways
- Internal linking patterns
- Content hierarchy
- Rendering behaviour
- Template architecture
Any one of those changes may influence how search engines interpret the website.
Several occurring simultaneously create considerably more complexity.
The strongest redesign projects tend to treat SEO as part of the planning process rather than a post-launch review.
Once rankings begin falling, recovery becomes more difficult.
Preventing the problem is almost always easier than repairing it afterwards.
The Cost of Losing Context
One issue rarely discussed during redesign planning is contextual continuity.
Search engines do not simply evaluate individual pages. They evaluate relationships between pages.
When websites are restructured, those relationships can change dramatically.
A page that once sat within a strong topical cluster may become isolated. Supporting content may lose direct pathways. Internal authority distribution changes.
The page itself remains online.
Its context changes.
That context often influences how search engines interpret expertise and relevance.
Preserving it should be considered a technical SEO priority rather than an afterthought.
Technical Debt: The Growth Constraint Nobody Notices Until It Becomes Expensive
Technical debt is one of the most useful concepts for understanding long-term SEO performance.
Unlike traditional technical errors, technical debt rarely produces immediate consequences.
It accumulates.
Slowly.
Almost invisibly.
A temporary workaround becomes permanent. A plugin remains installed long after it is needed. Legacy redirects are never reviewed. Multiple teams implement solutions independently. Content structures evolve without a unified framework.
None of these decisions seem significant individually.
Together, they create complexity.
Complexity increases maintenance requirements. Maintenance delays improvements. Delayed improvements create further complexity.
The cycle repeats.
Many websites reach a point where technical debt becomes a larger obstacle than any individual SEO issue.
Changes become harder to implement. Audits reveal increasingly interconnected problems. Small improvements require disproportionately large effort.
This is one reason technical SEO should be viewed as an ongoing discipline rather than a one-off project.
Healthy websites tend to manage complexity continuously rather than allowing it to accumulate indefinitely.
The Mistakes That Continue to Limit Organic Growth
Technical SEO evolves. Search engines evolve. User expectations evolve.
Interestingly, many of the same mistakes continue appearing year after year.
Focusing on Metrics Instead of Outcomes
It is easy to become distracted by individual SEO metrics.
PageSpeed scores, crawl reports and optimisation checklists all have value.
The problem emerges when the metric becomes the objective.
A technically healthy website is not defined by perfect scores. It is defined by its ability to support visibility, usability and growth.
Some organisations spend months chasing marginal technical improvements while overlooking larger structural issues affecting indexation and discoverability.
Priorities matter.
Assuming More Content Automatically Creates More Traffic
Content remains essential.
Yet content growth without supporting infrastructure often creates diminishing returns.
A website publishing hundreds of additional pages without addressing architecture, internal linking and crawl efficiency may simply create more complexity for search engines to process.
Growth strategies become more effective when technical foundations evolve alongside content production.
Treating Technical SEO as a Marketing-Only Function
Some of the most significant technical SEO decisions are made outside marketing departments.
Developers influence rendering behaviour. Infrastructure teams influence performance. Project managers influence implementation priorities. Content teams influence architecture through publishing decisions.
Successful SEO projects often depend on collaboration between multiple stakeholders.
That reality is frequently underestimated.
The most effective technical SEO environments are usually those where technical considerations become part of broader operational decision-making rather than existing as a separate marketing initiative.
The Hidden Business Cost of Ignoring Technical SEO
One reason technical SEO is sometimes neglected is that the costs are rarely immediate.
If a paid advertising campaign fails, the impact is visible quickly.
If technical quality deteriorates, the consequences often emerge gradually.
Traffic growth slows.
Content takes longer to perform.
Search engines become less efficient at discovering new pages.
Website migrations become riskier.
Future improvements require more effort.
The cumulative effect can be substantial.
In practical terms, technical SEO influences the return generated by almost every other digital investment.
Content marketing depends on discoverability.
Link acquisition depends on indexation.
Website development depends on maintainable architecture.
Organic growth depends on all of them working together.
This is why technical SEO should not be viewed as a standalone activity.
It is part of the operating system beneath the website.
When that operating system functions efficiently, growth becomes easier to achieve.
When it does not, every other initiative must work harder to compensate.
Not Every Technical Issue Deserves the Same Level of Attention
One of the biggest mistakes organisations make after completing a technical SEO audit is assuming that every recommendation should be treated as equally important.
In reality, some issues directly affect visibility, while others have little measurable impact beyond incremental improvement.
This distinction is important because technical audits can generate extensive lists of recommendations. Large websites may uncover dozens or even hundreds of observations. Without a prioritisation framework, teams often become overwhelmed and struggle to determine where effort should be focused.
The objective should never be to create a technically perfect website.
The objective should be to remove the obstacles most likely to restrict growth.
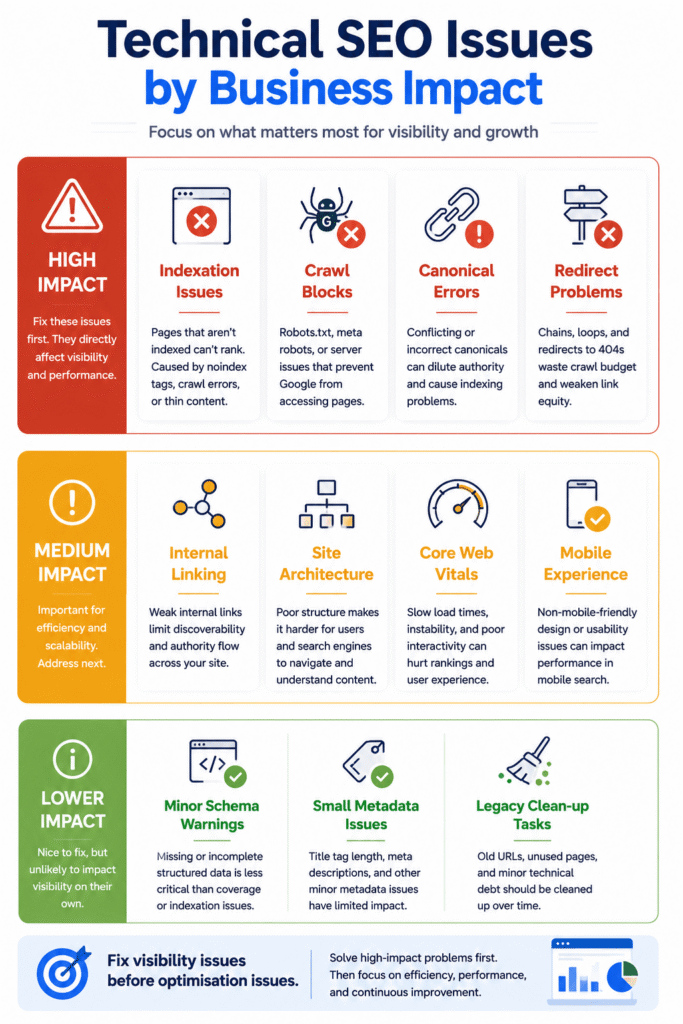
High-Impact Issues
The highest-priority technical problems are usually those that affect crawling, indexation or accessibility.
If important pages cannot be discovered, crawled or indexed efficiently, rankings become difficult regardless of how strong the content may be.
Examples often include major crawl restrictions, widespread indexation issues, broken internal architecture, incorrect canonical implementation and significant redirect problems.
These issues deserve immediate attention because they directly influence visibility.
Medium-Priority Improvements
The next layer typically involves areas that improve efficiency rather than solve critical failures.
Internal linking enhancements, schema improvements, architecture refinements, image optimisation and navigation adjustments often fall into this category.
These changes can contribute meaningfully to long-term performance, but they rarely represent emergency fixes.
They support growth rather than restore functionality.
Low-Priority Technical Refinements
Every website contains opportunities for further optimisation.
Not all of them justify immediate action.
Minor warnings, isolated technical observations and marginal efficiency improvements may still be worth addressing, but they should not distract attention from more significant constraints.
The most successful SEO teams understand that prioritisation is often more valuable than perfection.
A Practical Technical SEO Severity Framework
When reviewing technical issues, it can be helpful to evaluate them through three questions.
First, does the issue affect visibility?
Second, does the issue affect scalability?
Third, does the issue affect future growth?
The answers usually reveal where attention should be directed.
A broken canonical implementation affecting hundreds of pages is likely to influence all three areas.
A minor schema warning may influence none of them.
That does not mean schema should be ignored. It means context matters.
One reason technical SEO becomes overwhelming is that many audits present observations without explaining business impact. Recommendations become detached from commercial reality.
The strongest technical decisions are made when technical priorities and business priorities remain aligned.
What Strong Technical SEO Looks Like in Practice
There is a temptation to view technical SEO as a collection of individual fixes.
Improve speed.
Review redirects.
Update schema.
Check crawl reports.
Those activities matter, but they only tell part of the story.
Strong technical SEO is ultimately about creating a website that search engines can navigate with minimal friction and maximum clarity.
When technical foundations are healthy, content becomes easier to discover. Authority flows more effectively throughout the website. New pages gain visibility more efficiently. Growth becomes easier to sustain.
Perhaps more importantly, future changes become less risky.
Websites are never static assets.
They evolve continuously.
New services are launched. Content expands. Platforms change. Design trends shift. Customer expectations develop.
A technically healthy website is better equipped to absorb those changes without creating unnecessary SEO disruption.
The Future of Technical SEO Will Be Shaped by Complexity
Search engines continue evolving. Artificial intelligence is changing how information is processed and interpreted. Development frameworks are becoming increasingly sophisticated. Websites themselves are more dynamic than ever before.
Despite these changes, the underlying principles of technical SEO remain remarkably consistent.
Search engines still need to discover content.
They still need to access it.
They still need to understand it.
And they still need sufficient confidence to present it within search results.
The mechanisms may evolve, but the fundamentals remain.
What is changing is the level of complexity involved.
Modern websites increasingly rely on JavaScript frameworks, API-driven content, headless CMS architectures, dynamic rendering systems and interconnected technology stacks. These developments create new opportunities for businesses while introducing new technical considerations.
As a result, technical SEO is gradually becoming less about isolated optimisation tasks and more about ensuring accessibility within increasingly sophisticated digital ecosystems.
That trend is unlikely to reverse.
Final Thoughts
Technical SEO is often described as the foundation of organic search performance. While the phrase is frequently repeated, it remains accurate.
Most businesses naturally focus on visible aspects of growth. Content attracts attention. Branding attracts attention. Advertising attracts attention.
Technical infrastructure rarely does.
Yet it is often the factor that determines how effectively every other investment performs.
A technically healthy website allows search engines to discover important pages efficiently, understand relationships between topics, process content accurately and evaluate the website with greater confidence.
That does not guarantee rankings.
Nothing in SEO does.
What it does provide is a stronger platform upon which content, authority and long-term organic growth can be built.
For smaller websites, that may involve maintaining a clean structure and avoiding common mistakes.
For larger organisations, it often means managing complexity before complexity begins managing the website.
The most effective technical SEO strategies are rarely the most visible. They simply remove barriers that should never have existed in the first place.
And over time, that consistency tends to outperform short-term optimisation tactics.
Technical SEO is not about chasing perfect scores, obsessing over isolated metrics or fixing issues for the sake of fixing them. Its real purpose is creating an environment where search engines can access, interpret and trust a website as efficiently as possible. When that happens, every other aspect of SEO becomes more effective.
About the Author
This article was prepared by Serhii Kryvoviaz, CEO of Prime Lion Digital.
Serhii has worked across website development, technical SEO, SEO strategy, content architecture, UX optimisation and digital growth projects for businesses operating in a wide range of industries. His work focuses on the relationship between technical website infrastructure, search visibility, user experience and sustainable long-term business growth.
Drawing on practical experience from website audits, redesign projects, migrations and SEO recovery campaigns, this article reflects many of the technical patterns, challenges and opportunities commonly encountered across modern business websites.